
Shisa.aiを通して見る、日本のAI主権確立への試み
先日、日本で長年起業家として活動してきた外国人の友人と、現地での経験について話す機会がありました。彼は、「市場での競争以上に難しかったのは、日本特有のコミュニケーションの仕方に慣れることだった。」と語ります。
「相手が非常に丁寧な言葉を使っていても、それが本当に承諾を意味するのか、あるいは事実上丁重なお断りなのか判断できないことがある。」と、苦笑しながら例を挙げてくれました。実際、顧客に窓口の紹介を頼んだところ、相手は「検討してみます」と丁寧に答えたそうです。彼は当然、後日連絡が来るものと思っていましたが、結局そのメールが最後だったそうです。
このような話し方は、日本人がよく使う遠回しな断り方です。 「引き受ける気がないわけではないが、その場で明確に断ることが難しい状況」というニュアンスで、日本の文化に慣れていない人には誤解されやすい表現です。
私はこの話を聞いて非常に共感しました。言語とは単に単語を翻訳するだけではなく、話し方や文脈、さらにはお互いの暗黙の了解まで含まれるものだからです。
ふと、私たちが日常的に使っているAIのLLM(大規模言語モデル)のことを思い出しました。長い間現地で活動してきた企業家でさえ相手の意図を読み違えるのに、英語の文脈で学習されたAIモデルが、こうした文化的なニュアンスを正確に把握できるのでしょうか。
AIの文化的偏見
このような疑問は、MIT SLOAN(MITスローン)の最近の研究でも指摘されています。
研究チームは、OpenAIのChatGPTやBaidu(バイドゥ)のErnie(文心一言)などの大規模言語モデルを使って実験したことろ、モデルが使用言語によって異なる文化的偏見を示すことを確認しました。中国語で質問すると、「集団志向」の思考傾向が現れ、英語では「個人重視」な表現が顕著に表れたといいます。
例えば、大規模言語モデルに保険の広告スローガンを作ってほしいと頼んだ場合、中国語で入力すると「家族の未来はあなたの約束です」といったフレーズが、英語で入力すると「あなたの未来、あなたの平穏、私たちの保険」といったフレーズが生成されます。同じ質問でも、使用する言語によって反映される文化的価値観の優先順位がまったく異なるのです。

言語は単なるツールではなく、文化を伝える媒体だ。(画像:Xinyuan capital)
さらに重要なのは、これらの文化的傾向がユーザーに無意識のうちに影響を与え、AIが編集したメディアや教育資料を通じて社会全体に浸透する可能性があるということです。つまり、生成型AIは特定の文化や価値観をコピーしており、私たちが直接言語モデルを利用しなくても、そのモデルが築いた文化的視点や価値観の中に置かれている可能性が高いのです。そして多くの場合、私たちはそれに気づきません。
文化インフラ化する大規模言語モデル
言語モデルが内包しているのは、単なる技術ではなく、「文化」です。各ビッグスピーチモデルが生成する結果は、どの言い回しが「合理的」であり、どの反応が「正常」であるかを暗黙のうちに定義しています。私たちは、そのモデルを介して対話する過程で、背後にある価値の論理を受け入れているのです。
このため、多くの国が言語モデルを「主権ガバナンス」の観点で捉え始めています。欧州連合は2024年に人工知能法(AI Act)を可決し、初めて応用分野のリスクに応じて等級を分類するとともに、基礎モデルの開発者に対して訓練データの出所を公開するよう求めました。これは、モデルが反映する文化的価値を可視化し、統制力を確保するための取り組みです。
一方、シンガポールでは東南アジアの文化に合わせたオープンソースの大規模言語モデル「Sea-Lion(シーライオン)」の開発が進められています。東南アジアの言語や文化的背景を幅広く収集することで、現地のニーズに応えるAIを実現し、それを基盤とした新しいアプリケーションの構築も進んでいます。
サウジアラビアは国富ファンドを通じて直接介入し、皇太子主導のもと「Humain(ヒューメイン)」を設立しました。同社は、スーパーコンピューティングセンターや大規模データセンターの建設に着手しており、総投資額は1,000億ドル(約107億円)に上ります。
こうした多様な戦略には共通するメッセージがあります。言語モデルは単なるアルゴリズムではなく、「文化的価値」、「情報ガバナンス」、「国家の安全保障」とも関連があり、他者に依存せず自ら構築すべきだということです。
外国で訓練された言語モデルに長期的に依存することは、単にその国が定めた言葉遣いや対話のロジックを受け入れるにとどまらず、構造的なリスクを招きかねません。生成型AIが徐々に産業全体に浸透し、その学習データが特定の文化に偏っている場合、その価値観もまた社会全体に広がり、私たちの思考や表現のパターンを静かに再構築してしまう恐れがあります。
日本の挑戦:Shisa.ai、文化から生まれた言語モデル
言語理解をめぐる国際競争が進むなか、日本では「Shisa.ai」という注目すべき挑戦が生まれました。わずか3人という小規模なチームが、限られた資源をもとに4,050億パラメータ規模の日本語大規模言語モデルの学習を成功させたのです。実際のテスト結果によると、命令理解、翻訳、意味推論といった様々な日本語課題において優れた性能を発揮し、OpenAIのGPT-4や中国のDeepSeek-V3と同等の性能を示しました。小さなスタートアップにとって、これは単なる技術的達成にとどまらず、文化的主体性を具体的に示した意義ある成果といえるでしょう。

Shisa.aiは、自ら学習させた大規模日本語言語モデル「Shisa V2-405B」をリリースした。 (写真:Shisa.ai)
Shisa.aiの創業者3人はいずれも移民出身で、日本に定住し起業する道を選びました。彼らは、「AIの主権は現地の言語と文化から始まる」と考えており、自国モデルを構築することは単に多様性を守るだけでなく、データのプライバシー、地政学的な安定性、国家のデジタル主権にも深く関わっているとしています。
CEOのジア・シェン氏とCTOのレナード・リン氏は共同創業者であり、特にShisaモデルはレナード氏が主導して開発した代表作です。一方、チームのAI研究員であるアダム・レンセンマイヤー氏はまったく異なる経歴を持っています。彼は、日本のアニメファンに広く知られる字幕翻訳者であり、「進撃の巨人」、「ガンダム」、「名探偵コナン(劇場版)」、「銀河鉄道999」、「クレヨンしんちゃん」、「宇宙戦艦ヤマト」、「宇宙兄弟」など数多くの作品に携わってきました。その優れた言語感覚と語調への細やかなこだわりが、モデルの学習過程において重要な役割を果たし、Shisa.aiが日本語の奥深い文脈や文化的ニュアンスにより近づくことを可能にしました。
Shisa.aiは、当初から日本国内でモデルを学習させることを決め、日本語特有の言い回しや社会的なニュアンスといった特徴に意図的に焦点を当てました。創業者ジア・シェン氏は、こう語ります。「過去30年間で蓄積されたインターネット上の言語データは、ほとんど大規模言語モデルによって学習されてきました。しかし、AIの学習資料はやがて限界に達します。突破口となるのは、『より多くのデータ』ではなく『文脈に近いデータ』でしょう。例えば、オンライン上に自動で残らない声や感情がそれにあたります。」具体的には、高齢者同士の会話や地方の方言、Z世代のデート中の言葉遣いなど、言語と文化が混ざり合った実際の言語資源を誰が確保できるかが、次世代モデルの主導権を決定するとされています。
この構想は、日本政府からも支持を得ています。2024年、経済産業省はGENIAC(Generative AI Accelerator Challenge)プログラムを立ち上げ、資金、メンタリング、大規模な演算資源を提供することで、スタートアップが独自の基盤モデルを開発できるように支援しました。Shisa.aiはこのプログラムに選ばれたチームの一つであり、モデルの訓練速度を加速させることに成功し、日本の言語モデル研究開発における存在感を示しました。
印象的なのは、Shisa.aiが単なる技術開発にとどまらなかった点です。同社は、「話し方を理解する技術」を実際の産業現場に適用しました。例えば、日本の飲食店での外国人観光客対応、小売店舗における返品・交換業務のサポート、さらには駅に多言語対応のAI案内端末を設置し、旅行者への道案内や各種サービスを提供しています。この活用は、単なる技術的なデモンストレーションではなく、文化間のコミュニケーションに実践的に対応した事例といえます。
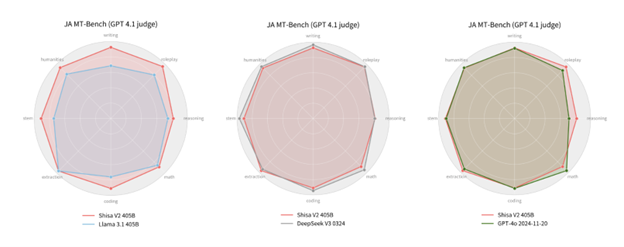
Shisa V2-405Bは、様々な日本語課題でOpenAIのGPT-4oや中国のDeepSeek-V3と同等の性能を示した。 (写真:Shisa.ai)
AIの言葉は誰の言葉を映すのか
Shisa.aiはまだ始まりに過ぎません。しかし一つの重要な事実を示しています。生成AIは急速に日常生活や産業全体に浸透しており、その話し方や言葉遣いは、私たちが互いを理解し、自分を表現する方法に大きな影響を及ぼすでしょう。
言語は単なる道具ではなく文化を伝える存在であり、私たちの話し方そのものが、AIが世界をどう理解するかを決定づけるのです。

記事執筆:Cherubic Ventures(チェルビックベンチャーズ)のマネジメントパートナー兼OurSongの共同創業者 Matt Cheng(マット・チェン)氏









