Kakao(カカオ)が独自の技術力を基盤に開発した次世代言語モデル「Kanana-2(カナナ-2)」をアップデートし、4種類のモデルをオープンソースで追加公開した。
Kanana-2は昨年12月、Hugging Face(ハギングフェイス)を通じてオープンソースで公開した言語モデルだ。Kakaoは1ヶ月ぶりに、性能をアップデートした4種類のモデルを追加公開した。
今回公開したモデルは、高効率・低コスト性能とともに、エージェンティックAI(Agentic AI)搭載のためのツールコーリング(Tool Calling)性能を強化したのが特徴だ。NVIDIA(エヌビディア)のA100レベルの汎用GPUでもスムーズに駆動できるよう最適化し、中小企業や学界の研究者たちも費用負担なく活用できるようにした。
Kanana-2の効率性の核心は「専門家混合(MoE, Mixture of Experts)」アーキテクチャだ。パラメータ全体は32B(320億個)規模で巨大モデルの性能を維持しつつ、実際の推論時には状況に合った3B(30億個)のパラメータのみ活性化して演算効率を高めた。MoEモデルの学習に必要な複数のカーネルを直接開発し、性能を損なうことなく学習速度を高め、メモリーの使用量を低くした。
データの学習段階も高度化した。事前学習(Pre-training)と事後学習(Post-training)の間に「ミッドトレーニング(Mid-training)」段階を新設した。AIモデルが新しい情報を学ぶとき、既存の知識を忘れる致命的忘却(Catastrophic Forgetting)現象を防止するため、「リプレイ(Replay)」技術を導入した。
Kakaoは基本(Base)モデル、指示履行(Instruct)モデル、推論特化(Thinking)モデル、ミッドトレーニング(Mid-training)モデルの4種類をHugging Faceに公開した。研究目的で活用度の高いミッドトレーニング探索用基本モデルを併せて提供し、オープンソースエコシステムの寄与度を高めた。
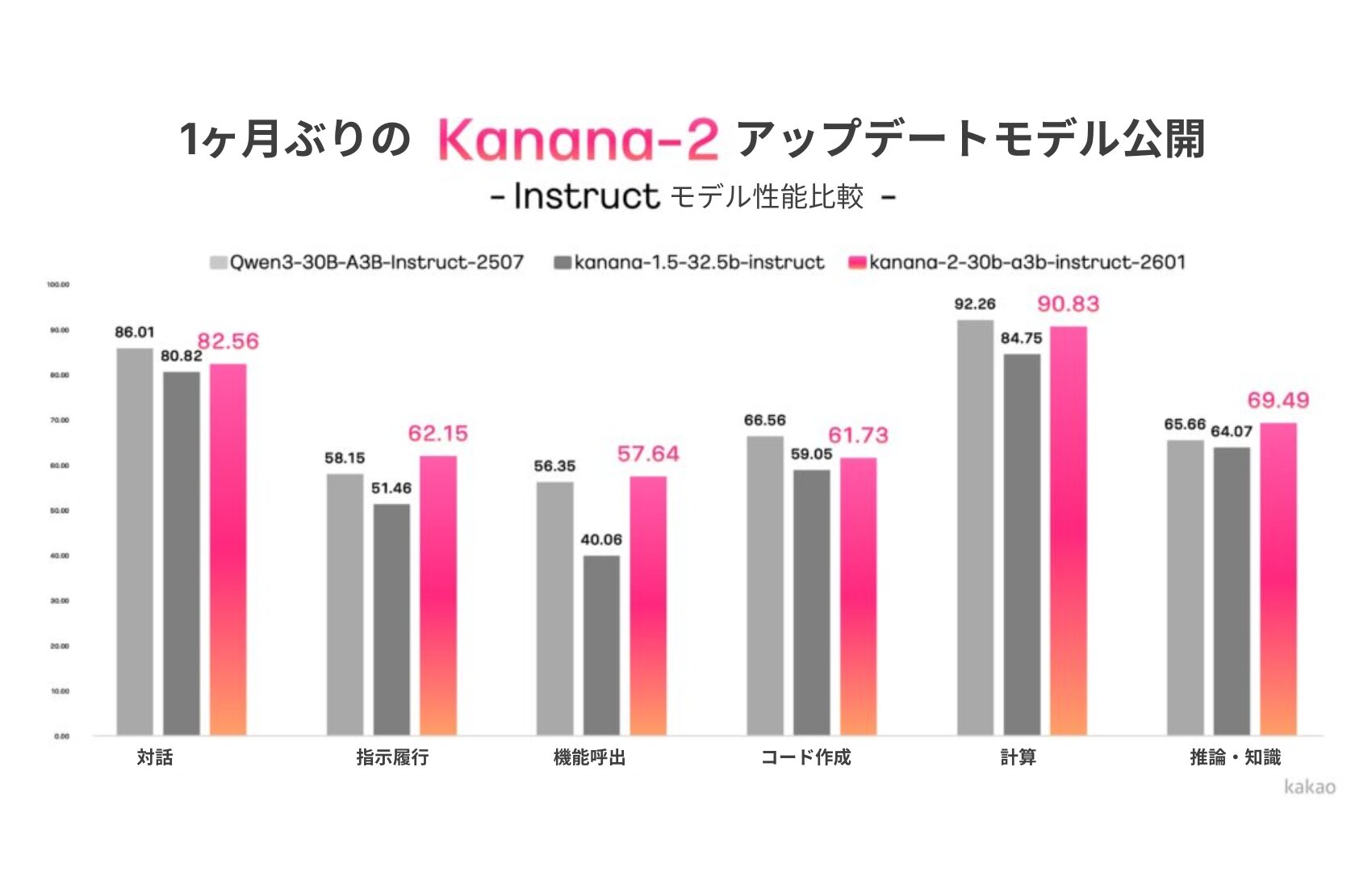
新しいKanana-2モデルは、シンプルな対話型AIを越えて、実質的な業務遂行が可能なエージェントAIの搭載に特化した。高品質なマルチターン(Multi-turn)ツールコーリング(Tool Calling)データを集中学習させ、指示履行とツールコーリング性能を強化した。性能評価で同級競争モデルである「Qwen-30B-A3B-Instruct-2507」に比べ、指示履行の精度、マルチターンツールコーリング性能、韓国語力などで優位な結果が出ている。
Kakaoは現在、MoE構造に基づき、数千億のパラメータモデル「Kanana-2-155b-a17b」の学習を進めている。中国のAIスタートアップ、ジプAI(Zhipu AI)の「GLM-4.5-Air-Base」モデル比40%のデータで学習させたが、MMLUなど主要ベンチマークで同様の性能を見せた。韓国語の質疑応答と数学領域では優位な結果を示した。
Kakaoのキム・ビョンハクKanana成果リーダーは「新しくなったKanana-2は、高価なインフラなしに実用的なエージェントAIを搭載できるか試行錯誤した結果だ」とし、「普遍的なインフラ環境でも高効率なモデルをオープンソースで公開することで、韓国のAI研究開発エコシステムの発展に寄与することを期待している」と話した。









