Kakao(カカオ)がテキスト、音声、画像を同時に処理できる統合マルチモーダル言語モデル「Kanana-o(カナナ・オー)」の性能を公開した。このモデルは、様々な形態の情報を統合的に理解し処理する能力を備えており、人工知能技術の新たな地平を開いたとの評価を受けている。
Kakaoは公式テックブログを通じて「Kanana-o」とオーディオ言語モデル「Kanana-a」の性能及び開発プロセスを詳細に共有した。今回公開された「Kanana-o」は、テキスト、音声、画像のいずれの組み合わせで質問を入力しても処理でき、状況に合ったテキストや自然な音声で回答が可能だ。
Kakaoの研究陣は「モデルマージング(Model Merging)」技術を活用して、画像処理に特化した「Kanana-v」とオーディオの理解及び生成に特化した「Kanana-a」モデルを効率的に統合した。その後、画像、オーディオ、テキストデータを同時に学習する「Joint Training(ジョイントトレーニング)」を通じて、視覚と聴覚情報を同時に理解し、テキストと連結できるよう訓練した。
「Kanana-o」は音声感情認識技術を通じてユーザーの意図を正確に解釈し、適切な反応を提供する。イントネーション、話し方、声の震えなど、非言語的な信号を分析し、会話の脈絡に合った感情的で自然な音声応答を生成するのが特徴だ。
大規模な韓国語データセットを活用して韓国語の特殊な発話構造とイントネーション、語尾変化などを精密に反映し、済州(チェジュ)島、慶尚道(キョンサンド)など、地域の方言を認識して標準語に変換する能力も備えている。Kakaoは現在、独自の韓国語音声トークナイザーの開発を進めている。
ストリーミング方式の音声合成技術を適用して、ユーザーが長い待ち時間なしに応答が受けられる利点もある。例えば、画像とともに「この絵にふさわしいおとぎ話を作って」と入力すると、「Kanana-o」はその音声を理解し、ユーザーのイントネーションと感情を分析して自然で創造的な話をリアルタイムで生成して聞かせてくれる。
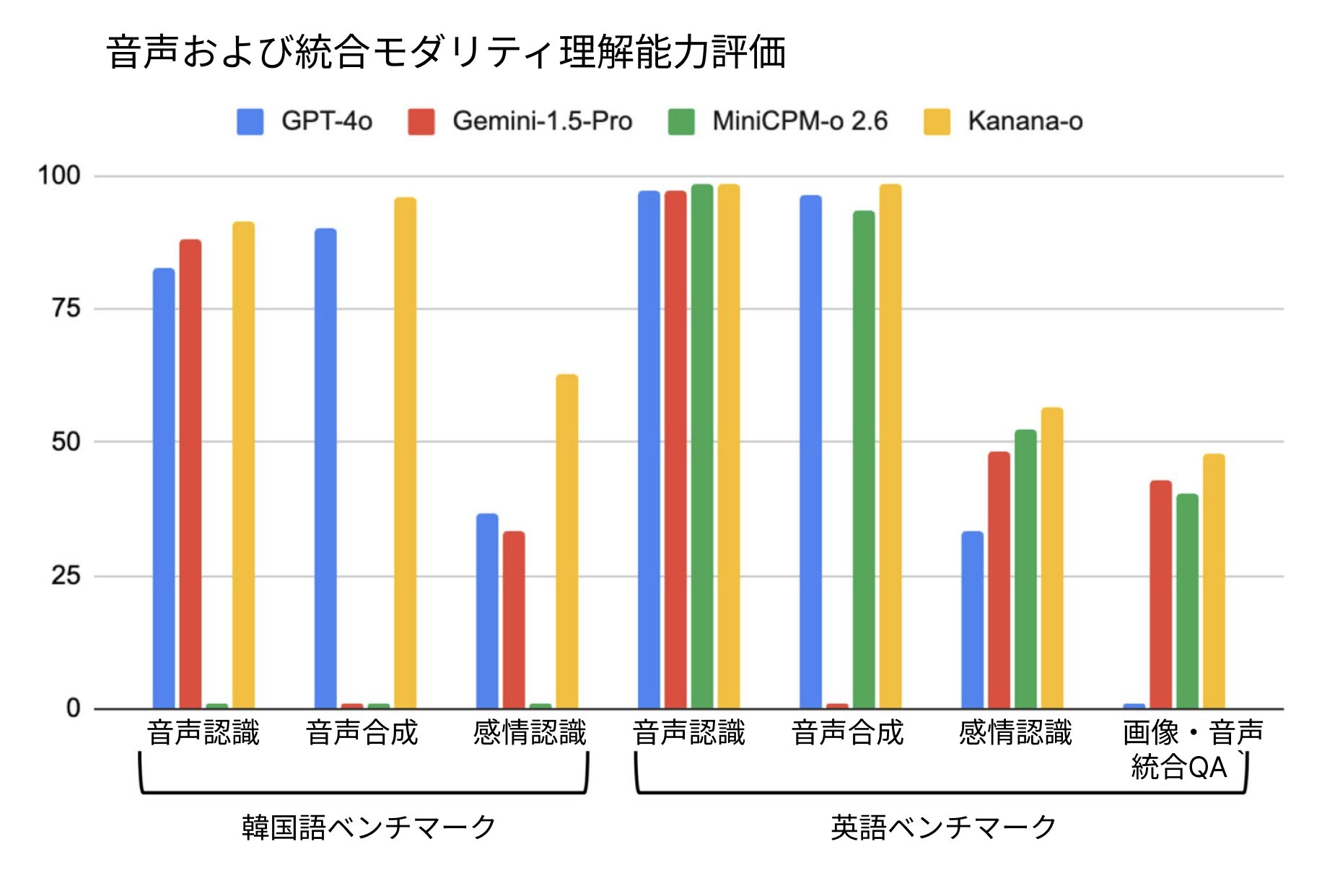
ベンチマークテストで「Kanana-o」は韓国語と英語の評価でグローバルトップモデルと同レベルの性能を見せ、特に韓国語ベンチマークでは優位を示した。感情認識能力では、韓国語と英語の両方で大きな差を見せ、感情まで理解して疎通できるAIモデルの可能性を立証した。
Kakaoは今後、「Kanana-o」を通じてマルチターン対話処理、Full-duplex対応能力の強化、不適切な応答防止のための安全性確保などを目標に、研究開発を継続する計画だ。これにより、マルチ音声対話環境でのユーザー体験を革新し、実際の会話に近い自然な相互作用を実現させることが目標だ。
Kakaoのキム・ビョンハクKanana成果リーダーは「Kananaモデルは複合的な形態の情報を統合的に処理することで既存のテキスト中心のAIを越えて、人のように見て聞いて話し共感するAIに進化している」とし、「独自のマルチモーダル技術を基に、自社の人工知能技術の競争力を強化する一方、持続的な研究結果の共有を通じて、韓国のAIエコシステムの発展に寄与し続けていく計画だ」と明らかにした。
Kakaoは昨年、自社開発のAIモデル「Kanana」のラインナップを公開し、公式テックブログを通じて様々なモデルの性能と開発過程を共有してきた。今年2月には韓国のAIエコシステム活性化のため、「Kanana Nano 2.1B」モデルをオープンソースでGithub(ギットハブ、プログラムのソースコードをオンラインで共有・管理するサービス)に公開。自社開発言語モデル「Kanana」の研究成果を盛り込んだテクニカルレポートをアーカイブに残した。









